Special thanks to Barnabé Monnot at the Ethereum Foundation for his help in answering my many questions.
1 Background & Context
The ‘Merge’ refers to Ethereum’s upcoming transition from using a Proof-of-Work consensus mechanism to a Proof-of-Stake consensus mechanism, and is currently scheduled for mid-September 2022.
This however begs the question: what comes after? What’s left for Ethereum to do after it moves to Proof-of-Stake, a stated goal since 2014?
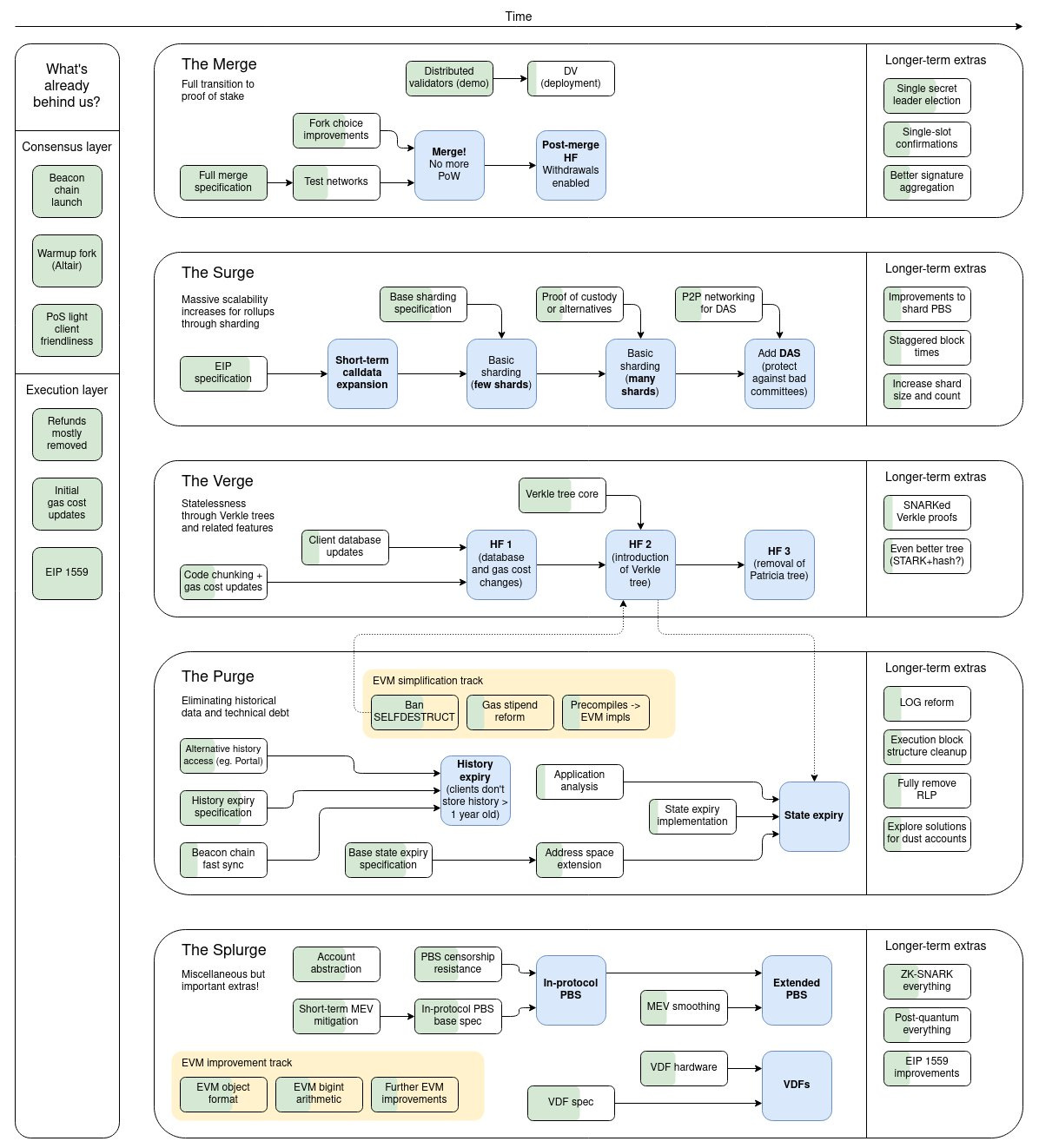
The answer: plenty! On 2 December 2021, Vitalik Buterin shared a diagram showing Ethereum’s other post-Merge protocol development roadmaps - namely the Surge, Verge, Purge & Splurge (!) :
It should be noted that these post-Merge roadmaps are not sequential to each other but are being worked on concurrently (see Time’s arrow along the top).
The purpose of this post is to discuss the Surge in more detail, including how things have changed for this roadmap since this diagram was published. The other roadmaps will be covered in a future post.
Before we can really get stuck in though, and in order to fully appreciate what the Surge is aiming to achieve and which aspects of the Ethereum protocol it is going to impact, we first need to provide a little context and remind ourselves about (1) the blockchain trilemma, (2) the different layers that comprise a blockchain, (3) rollups.
If you are new to this area, I would recommend reading my previous post first, which includes an explanation of how Ethereum will work under Proof-of-Stake as it will provide some useful context to this whole discussion, and also introduces terms that I may not necessarily re-define here.
Thanks for reading himesh.eth! Subscribe for free to receive new posts and support my work.
1.1 The blockchain trilemma
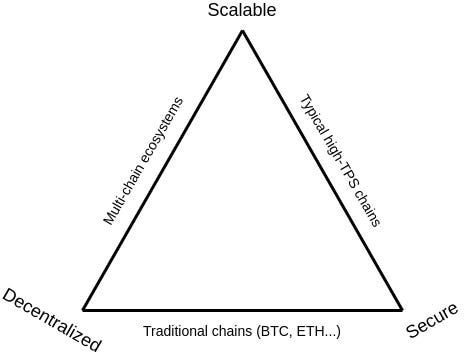
You have likely come across this trilemma before; it was first proposed by Vitalik Buterin back in 2017, and later visualised in another post in 2021:
The blockchain trilemma states that there are three properties a blockchain can try to have, and that, when sticking to ‘simple’ techniques, a blockchain’s developers can only optimise for two of those three at any given time.
The three properties are:
Scalability, i.e. the blockchain can handle a high throughput of transactions, usually measured as transactions-per-second (TPS).
Decentralisation, i.e. there are many ‘consensus’ full nodes securing the network by storing the blockchain data and/or verifying validated blocks and subsequent state changes.
Security, i.e. the blockchain can resist a large percentage of ‘validation’ full nodes (i.e. those that propose and/or validate blocks) trying to attack it.
So what kinds of blockchains emerge from optimising for only two of these three properties?
Traditional blockchains (e.g. Bitcoin, Ethereum): These rely on many consensus nodes verifying transactions, and as such the chains are decentralised and secure; but this self-same reliance on each node having to verify each transaction means that the TPS (and hence scalability) of these blockchains is constrained by the (intentionally) limited hardware requirements to run a node. As such, there is a balance to be struck between increasing node hardware requirements (which would lead to more powerful nodes being able to verify more transactions, increasing TPS and opening up the possibility of bigger blocks) versus these increased requirements pricing out more people from running nodes, and hence worsening decentralisation and security.
High TPS blockchains (e.g. Solana): These rely on a relatively small number of nodes validating blocks and maintaining consensus among themselves, with users having to trust a majority of these nodes. (These blockchains may also employ a system whereby these nodes act as delegates for users wishing to stake their coins.) These arrangements make a blockchain scalable and secure, but not particularly decentralised.
Multi-chain ecosystems (e.g. Cosmos): These ecosystems involve different applications living on different chains (‘app-chains’) and use cross-chain-communication protocols to bridge between them. This is decentralised and scalable, but it is not particularly secure as an attacker needs only to get a full node majority in one of the many chains to break that chain and possibly cause ripple effects that cause great damage to other connected chains, or the application within them.
As much as this pertains to Ethereum, the main question is: How does the Ethereum protocol increase scalability without compromising the existing strong decentralisation and security of the chain, and thus ‘solve’ the trilemma? Keep this question in your mind as you read on.
1.2 The different layers of a blockchain
Whilst it’s tempting to simply think of a blockchain as a series of blocks being linked together over time, the stages which encapsulate this process can be contextualised as three different ‘layers’: execution, data availability, and consensus.
Execution layer: This layer refers to the transaction requests that should get executed when they are included in any given proposed block by a block proposer (i.e. a miner or validator).
Data availability layer: This layer refers to the transaction data from proposed blocks that the block proposer needs to broadcast and make available to the network so that full nodes1 can verify the block proposer’s work.
Consensus layer: This layer refers to the overall consensus mechanism used by the blockchain, specifically:
the Sybil resistance mechanism used, in terms of either mining (in the case of Proof-of-Work) or proposing (in the case of Proof-of-Stake) as a method of collating valid transaction requests into a block, and
the chain selection rule used, in terms of the act of verification of the mined/proposed block performed by full nodes and its eventual appending onto the tail of the blockchain.
Now we have this high-level understanding of the three layers, we can see that Ethereum’s upcoming transition from Proof-of-Work to Proof-of-Stake is actually a significant change to the consensus layer of the blockchain only - the execution and data availability layers remain unchanged.
This transition being called the ‘Merge’ actually refers to the ‘merging’ of the execution and data availability layers of Ethereum with the new consensus layer provided by what’s called the ‘Beacon Chain’2. Under Proof-of-Stake, miners are being replaced with validators; and as all validation nodes are known to the Beacon Chain, it can coordinate them and assign them roles to facilitate the validation process.
The Surge itself is focused on resolving bottlenecks in the data availability layer which will emerge as a result of rollups becoming Ethereum’s main execution engine.
So, what are rollups?
1.3 Rollups
In 2020, Ethereum announced its intention to lean in fully to a rollup-centric roadmap. What does this mean?
Well, everything I just wrote above around execution, data availability and consensus layers refers to the Ethereum blockchain, which is alternatively called the Ethereum main network (or mainnet). Let’s now call this Ethereum mainnet a ‘Layer 1’ blockchain (this use of capital-L ‘Layer’ should not be confused with the other three lowercase ‘layers’ - confusing, I know).
Let’s now imagine a Layer 2 blockchain, existing separate to the Layer 1, executing transaction requests from users interacting directly with it, and maintaining its own state. In Layer 2 terminology, the specific node processing these transactions is called a sequencer.
Furthermore, let’s imagine this Layer 2 sequencer then ‘rolls up’ hundreds of these transactions into a single bundle and submits this bundle wholesale (with the accompanying underlying transaction data) as a single transaction onto the Layer 1’s execution layer.
(You may see the Layer 1’s execution layer also be referred to as a settlement layer in this context as the rolled up transactions are being ‘settled’ on it.)
By regularly posting these bundled transactions onto the Layer 1’s execution layer, the Layer 2 (which can now simply be called a rollup in this instance) allows the transactions within these bundles to use the consensus layer of the Layer 1, inheriting its superior security and decentralisation. (And to reiterate: the Layer 1 execution layer does not execute the Layer 2 transactions; this action is performed at the Layer 2 level.)
The Layer 1’s execution layer itself also benefits as the Layer 2 removes these transactional loads from the Layer 1’s execution layer - them being a key source of congestion - which in turn improves scalability at the Layer 1’s execution layer. What’s even better is that all of this requires no changes to the Layer 1 protocol.
There are two types of rollups worth noting:
Optimistic rollups are ones where the transactions are trusted to be valid by the Layer 1 by default. The Layer 2 sequencer attests to this validity and posts collateral called a deposit to back it. However, the Layer 2 has its own independent verifier nodes that will process the transactions themselves and will be able to raise a challenge if they get a different result, providing their own deposit as collateral to back the challenge. When there is a challenge, a fraud proof computation will get posted to the Layer 1 as another transaction and all Layer 1 full nodes will run and verify the fraud proof computation as part of their normal transaction execution process. Whichever of the two parties is wrong loses their deposit, and all transactions that depend on the result of that computation are recomputed.
Zero knowledge (or ZK) rollups involve a form of cryptographic proof (or validity proof), published by the sequencer (or a separate prover), that directly proves that the transactions posted from the Layer 2 sequencer are valid. It’s impossible to produce a validity proof for an invalid block.
In both of these cases, large amounts of underlying transaction data are posted onto the Layer 1. The speed at which this Layer 2 can post all of this data (and hence ultimately the speed at which this Layer 2 can have its transactions finalised) is limited by the throughput of the underlying data availability layer of the Layer 1.
As such, scalability solutions need to be found at the data availability layer.
(There is an associated underlying question here: How can we be sure that the Layer 2 is truly posting all of the data in the first place, and not withholding any information? This is known as the data availability problem and it’s something we’ll be discussing further below.)
1.4 Bringing it all together
To quickly recap the above:
Ethereum is a ‘traditional’ blockchain currently emphasising decentralisation and security over scalability.
Scalability solutions can be sought at both the execution and data availability layers of the blockchain.
Execution layer scaling is aimed to be achieved through rollups, which remove heavy transactional loads away from the Layer 1 to an off-chain Layer 2.
However, this solution will still face throughput bottlenecks at the Layer 1 data availability layer when these Layer 2 rollups start posting large amounts of transactional data onto the Layer 1.
And so the next major development of Ethereum is aiming to remove these bottlenecks by implementing scalability solutions at the data availability layer.
Which brings us (at last!) onto…
2 The Surge
The Surge is one of Ethereum’s next major milestones, improving scalability at its data availability layer through something called data sharding.
Data sharding, in its simplest sense, seeks to split the large amounts of transaction data (or shard blobs) in a block ‘horizontally’ across many sub-networks or shards to spread the load, allowing validation processes to run in parallel with an ultimate aim to reduce congestion and increase transactions-per-second.
Ethereum’s plans for data sharding have shifted quite considerably in the past few months. Let’s start with what they were going to be, as it provides some (more) useful context and allows us to discuss another concept - the data availability problem -which is critical to understand where things are going.
2.1 The original data sharding design
2.1.1 Design overview
The initial plan was laid out here under the section titled ‘Sharding through Random Sampling’. In this iteration, the plan was to have 64 shards set up to split out the data from the block produced in each slot, with each shard assigned their own proposers and 128-node validator committees chosen through random sampling from the total validator set.
This random sampling exercise to assign proposers and validator committees would take place at the start of every epoch (a measure of time covering 32 slots).
In each slot, proposers for each shard would have been entitled to propose a shard blob consisting of, amongst other data3, a sampling of transactions from the main block. When a validator from a committee verified a shard blob, they would have had to publish a signature attesting to the fact that they did so. The main block would only have been appended to the end of the blockchain once a majority of the committees in every shard had provided attesting signatures. In terms of wider consensus, the other full nodes would have only had to verify the committee signatures rather than the shard blobs themselves4.
There was one particular weakness with this implementation: It relied on an honest majority of validators from each shard’s validator committee to fully download the data for that shard and provide their attesting signatures.
Ideally, we want to avoid relying only on such an arrangement and find a way to utilise all of the full nodes, including the validation nodes when they’re not performing their proposer/committee tasks, to meaningfully verify the data in the whole block, ideally without having to all download all of the data themselves, hence preserving the security that Ethereum gets from full verification.
What does ‘meaningfully verify’ above really mean? Two things:
Ensure that the all of the data is being made available.
Ensure that all of the transactions are valid.
The first item is our aforementioned friend - the data availability problem. The key to solving this is with a technique called data availability sampling.
2.1.2 Ensuring data availability with data availability sampling
Vitalik explains how data availability sampling works succinctly here, reproduced below:
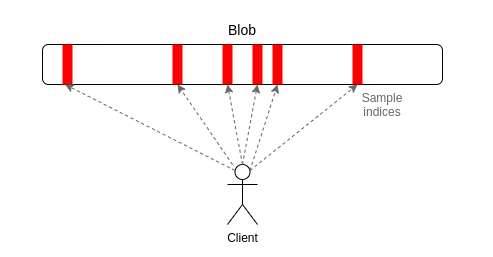
Use a tool called erasure coding to expand a piece of data with N chunks into a piece of data with 2N chunks such that any N of those chunks can recover the entire data.
To check for availability, instead of trying to download the entire data, users simply randomly select a constant number of positions in the block (eg. 30 positions), and accept the block only when they have successfully found the chunks in the block at all of their selected positions.
[Note that ‘indices’ shown here refers to the same thing as ‘positions’ in the main text.]
Erasure codes transform a "check for 100% availability" (every single piece of data is available) problem into a "check for 50% availability" (at least half of the pieces are available) problem. Random sampling solves the 50% availability problem. If less than 50% of the data is available, then at least one of the [position] checks will almost certainly fail, and if at least 50% of the data is available then, while some nodes may fail to recognize a block as available, it takes only one honest node to run the erasure code reconstruction procedure to bring back the remaining 50% of the block. And so, instead of needing to download 1 MB to check the availability of a 1 MB block, you need only download a few kilobytes. This makes it feasible to run data availability checking on every block.
So each full node performing data availability sampling on each block allows it to verify that all the transaction data is being made available, whilst downloading only a few kilobytes per block even if the block as a whole is a megabyte or larger in size. A full node then only accepts a block when all data availability challenges (i.e. position checks) have been correctly responded to5.
Data availability sampling itself requires two conditions that must be met in order for the block to be able to be reconstructed:
Honest minority: There are a sufficient number of full nodes collectively making enough data availability sampling requests that the responses almost always overlap to comprise at least 50% of the block, so the block itself can be reconstructed.
Synchrony: The nodes need to be able to communicate within some period of time to be able to put the block back together.
2.1.3 Ensuring transaction validity
So now, having verified data availability, how can full nodes then verify the correctness of this data, i.e. that all the transactions contained in the block are valid?
If the Layer 2 is an optimistic rollup, as previously stated, the validity of the transactions is trusted by the Layer 1’s full nodes by default, however if the Layer 2’s own independent verifier nodes post a fraud proof to the Layer 1, all Layer 1 full nodes will run and verify the fraud proof computation. This should be an extremely rare occurrence due to the collateral deposits at stake on either side.
If the Layer 2 is a zero knowledge (or ZK) rollup, it’s a lot simpler: each block would already come with a validity proof proving correctness, which each full node can trivially verify and attest to. As previously stated, you cannot make a validity proof for an invalid block.
So, with a combination of data availability sampling and either performing rare fraud proof computations / verifying validity proofs, each full node only needs to do a small amount of verification work per block, no matter how big the block is, and without needing to download the whole block’s data.
2.1.4 Other issues with the original data sharding design
These full node verifications, complemented by the verifications performed by the validator committees, was seen at the time as the best way to bring secure scalability to Ethereum. But it was not meant to be. This original data sharding design with multiple shard proposers and committees still had other issues:
There is a much larger amount of raw data that would have been needed to be passed around, increasing the risk of failures under extreme networking conditions.
Each subnet would have been easier to attack because it had fewer nodes. On a related note, effectively penalising this attacker would have been difficult as only a very small portion of their deposits (the deposits backing the validation nodes that participated in that particular committee) would be provably implicated in the malicious behaviour and could conceivably be penalised.
Shuffling validators around between shards would have been technically complex.
Reliance on a large number of validators per epoch - at a minimum 262,144 (32 slots per epoch * 64 shards * 128 minimum committee size). Note however that if validation node numbers had reduced below this, the number of active shards would have reduced automatically to ensure that committee sizes remained sufficient even under conditions of low participation.
It would have been very difficult for the validator committee shard attestation process to have been completed within a single slot (set at 12 seconds post-Merge) .
In recent months, this planned design has been effectively superseded by another, colloquially called danksharding after its author Dankrad Feist.
2.2 Danksharding
2.2.1 Design overview
In the previous design, we had 64 data shards. In each slot, 64 proposers independently proposed their shard blobs, which were then to be verified by validator committees, which itself could take longer than that single slot.
Danksharding’s design, initially shared here, was quite different:
Here is an alternative proposal: Add a new type of transaction that can contain additional sharded data as calldata. The block is then constructed by a single block builder (which can be different from the proposer using proposer builder separation), and includes normal transactions as well as transactions with sharded calldata.
Danksharding suggests a return to using single blocks (rather than explicit shards), created by individual builders, with all of the necessary transaction data being included directly within these blocks. Due to the size of these blocks, no full nodes would be expected to download all of the data in them, relying on other ways to verify data availability and transaction validity.
Note that Dankrad’s design above also mentions that the block builder can be separate from the proposer. This is a key aspect of the design, and in line with the current thinking on how to build a scalable and secure long-term blockchain ecosystem - i.e. that it will inevitably involve centralised block production with decentralised block validation. It’s worth delving into this separation of roles in more detail.
(It’s also worth noting that proposer-builder separation is a key development of the Splurge roadmap, which we’ll discuss in more detail in a future post.)
2.2.2 Proposer-builder separation
Under Ethereum’s implementation of Proof-of-Stake, one validator is randomly selected via an algorithm to be a combined block builder & proposer in every 12-second slot. This validator is responsible for both building a new block and then sending it out (i.e. proposing it) to the other nodes on the network.
Under proposer-builder separation (PBS), the ‘building’ aspect of the validator’s role is separated out and set up as a specific new role in the protocol. Specialised builders, with more powerful hardware than that used by standard full nodes, are expected to build big blocks with lots of transaction data and then bid for proposers (i.e. validators) to select their block6.
We need one honest builder to service the network for liveness and censorship resistance (and two for an efficient market), but validator sets require an honest majority. PBS makes the proposer role as easy as possible [in order] to support validator decentralization.
Builders receive priority fee tips plus whatever MEV [maximal extractable value] they can extract. In an efficient market, competitive builders will then bid up to the full value they can extract from blocks (less their amortized costs such as powerful hardware, etc.). All value trickles down to the decentralized validator set – exactly what we want.
The precise implementation of PBS is still being finalised. In the current thinking, a slot is split into two stages:
In the first stage:
Builders build blocks in a way such that it maximises the value they can extract from them, e.g. from capturing the transactions with the highest priority fee tips.
Independently, a proposer is randomly selected from the validation nodes via an algorithm.
Builders submit their block headers to the chosen proposer along with their bids.
Only block headers, and not the full block bodies with all the transaction data, are shared at this stage in order to save bandwidth and also prevent worse builders from figuring out others’ high-MEV strategies and stealing them to quickly submit another header.
Additionally, sophisticated proposers could also steal the high-MEV strategy used if it was detectable and submit it using their own builder, stealing the MEV, and leading to a dangerous unification of proposer and builder.
The proposer chooses the winning block header and is immediately paid the winning bid unconditionally, even if the builder fails to produce the block body at the next stage. This unconditional payment removes the need for the proposer to trust the builder.
A single validator committee attests to the winning header.
In the second stage:
The successful builder then reveals the body for the winning block header.
The remaining N-1 validator committees (where N is the total validator set / 32 slots per epoch / 128 minimum size per committee) attest that the revealed block body is indeed associated with the winning block header (or confirm that it was absent if the winning builder withholds it or fails to publish it in time).
If the block body is not presented by the builder for whatever reason, the builder will lose out on the MEV and fee tips.
Following further verifications around data availability and transaction validity from full nodes (discussed further below), the winning block is appended onto the end of the blockchain.
In this implementation, each stage takes 8 seconds, so a slot would have to increase from its post-Merge 12 seconds to 16 seconds, i.e. a 16 second ‘block time’ in which to build-propose-verify-append a block over two stages7.
2.2.3 Censorship resistance list
In setting up an auction market for block selection, there’s one major issue which may arise: if a builder was so inclined, they could censor transactions they didn’t want included in the blocks by overbidding other builders for their block to be chosen (with those transactions excluded), even though it would be at a loss to the censoring builder8.
How can we allow for this? With something called a censorship resistance list or ‘crList’. A ‘crList’ is intended to put a check on the builder’s power under PBS. As with PBS itself, the precise crList implementation hasn’t been finalised yet but currently, ‘hybrid PBS’ is the frontrunner, operating over the same two PBS stages:
In the first stage:
The proposer publishes a crList (and accompanying ‘crList summary’) which specifies all eligible transactions they see in the mempool.
Builders build their blocks and submit their block headers and bids as before, except now they also include a hash of the crList summary proving they’ve seen it. Note that the builders are forced to include the crList transactions unless/until the block is full.
In the second stage:
The successful builder reveals the body for the winning block header as before, and now also includes a proof they’ve included all transactions from the crList (or that the block was full).
Now this implementation of the crList has its own issues, for example the dominant economic strategy here is for a proposer to submit an empty list. This would allow any outbidding, censoring builders to win the auction, whilst also allowing the proposer to pocket the highest bid. This could be resolved by having multiple validators publish their own crLists, but that plan would probably have its own wrinkles.
Overall, it’s generally worth noting that this is still an ongoing area of discussion and development.
2.2.4 Ensuring data availability with data availability sampling using validation nodes
Before a block can be appended onto the end of a blockchain, further verifications need to be performed around data availability and transaction validity. We’ll discuss here how validation nodes ensure data availability under danksharding.
With danksharding, as with the original data sharding design, all of the validation nodes are utilised for every epoch. Here, the whole validator set is split into 32 groups (one for each slot in an epoch), with each group providing attestations around data availability for the block associated with their assigned slot.
A similar type of ‘position hunting’ sampling of erasure-coded data is performed as for the original data sharding design, however validators are required to download assigned positions for both their own block and for other blocks as well.
Validators would only be able to attest to their assigned positions in their assigned slot, if their assigned position were also available for every other block between their current assigned slot and the previous slot they attested to in the previous epoch.
For example, a validator would be able to attest to their assigned positions in slot 7 of epoch 2 if their assigned positions were also available in every slot since the last block the validator was assigned to attest for, say, slot 19 of epoch 1.
This process relies on an honest majority of validators to attest that the whole block’s data is available.
2.2.5 Ensuring data availability with data availability sampling using consensus nodes
Similar to when we considered the original data sharding design, we want to avoid relying only on honest majority assumptions and find a way to utilise the consensus (i.e. non-validation) nodes to continue meaningfully verifying the data in each block, ideally without having to all download all of the data themselves, hence preserving the security that Ethereum gets from full verification.
This sort of verification is intended to be brought in with private random sampling. This is where each consensus node checks c.75 random positions from the erasure-coded blocks. This is currently proving a hard nut to crack in terms of its actual practical implementation, but work is ongoing.
Note the ‘private’ aspect of this is important here as if an attacker has de-anonymised you, they will be able to just return you the exact chunks you requested and withhold the rest, so you wouldn’t know from your own sampling alone that all data was made available.
2.2.6 Ensuring transaction validity
This should function in pretty much the same way as for the original data sharding design:
If the Layer 2 is an optimistic rollup, as previously stated, the validity of the transactions is trusted by the Layer 1’s full nodes by default, however if the Layer 2’s own independent verifier nodes post a fraud proof to the Layer 1, all Layer 1 full nodes will run and verify the fraud proof computation. This should be an extremely rare occurrence due to the collateral deposits at stake on either side.
If the Layer 2 is a zero knowledge (or ZK) rollup, it’s a lot simpler: each block would already come with a validity proof proving correctness, which each full node can trivially verify and attest to. As previously stated, you cannot make a validity proof for an invalid block.
So, once again, with a combination of data availability sampling and either performing rare fraud proof computations / verifying validity proofs, each full node still only needs to do a small amount of verification work per block, no matter how big the block is, and without needing to download the whole block’s data.
2.2.7 Benefits of danksharding with PBS and crList
Tighter integrations between rollups and the Layer 1:
No need to track or wait for separate shard blob confirmations; both Layer 1 and shard blob transaction data is now able to be confirmed together (i.e. synchronous calls) on the main Ethereum chain because everything is produced in the same big block and immediately visible.
No need to worry about duplicate shard data.
A merged fee market. The existing Ethereum transaction payment infrastructure can be used as is. The original data sharding design with distinct shard blobs by separate proposers would have fragmented this.
The removal of separate shard committees…
…reduces complexity - only one committee is required per slot whilst 64 committees would have been required per slot (one for each shard) in the original data sharding design.
…strengthens bribery resistance as the data is being verified by larger committees (1/32 of the total validation set verifying the whole block vs 1/20489 of the total validation set verifying each shard).
Using big blocks means data availability sampling is more efficient in terms of bandwidth.
Danksharding brings a lot of benefits and is planned to be the end-state of data availability layer scaling, i.e. the end-state of the Surge as it is currently envisaged. But it’s still a work in progress, and is unlikely to be implemented until sometime well into 2023 (if not later).
In the meantime, focus has shifted to an interim solution - proto-danksharding (PDS) - which could be implemented a lot sooner, even by the end of 2022 if there’s enough of a concerted effort between now and then to get development over the line. Although an interim solution, PDS would significantly increase throughput whilst also reducing fees for users. As our last stop on the Surge tour, let’s dive into that now.
2.3 Proto-danksharding (EIP-4844)
2.3.1 Design overview
At this current moment, when rollups post their bundled transactions as a single transaction on the Ethereum execution layer, the underlying transaction data in these single transactions is stored as a specific data type called calldata, stored on-chain permanently. There’s only a certain amount of calldata capacity available per block, and so rollups are very dependent on gas prices on Ethereum and the competitiveness of the blockspace.
Even in Dankrad’s original proposal, he envisaged using calldata:
Add a new type of transaction that can contain additional sharded data as calldata.
In consideration of this, protolambda, an Ethereum Researcher, has submitted an Ethereum Improvement Proposal (EIP) 4844 which introduces a new type of transaction called a blob-carrying transaction. A blob-carrying transaction is just like a regular transaction, except it also carries an extra piece of data called a blob. Blobs are designed to carry a large amount of data whilst also being much cheaper in gas costs compared to storing this same amount of data as calldata.
This is possible because PDS introduces a bifurcated fee market, where there are now two resources, gas and blobs, each having their own independent floating gas prices. This means blobs are not competing with the gas usage of existing Ethereum transactions, and so sidestep the current gas price competition for blockspace. The Ethereum Virtual Machine (EVM) - which maintains Ethereum’s state - can’t directly access the blobs but can view the commitments10 attached to the blobs; the blobs themselves are stored in Ethereum’s consensus layer (the ‘Beacon Chain’) instead of the execution layer.
In a similar vein to danksharding, PDS sticks with single big blocks with all of the necessary transaction data being included directly within these blocks, except now there will be a new blob-carrying transaction type. It would be expected that danksharding, if and/or when it is implemented in the future, will also use blobs rather than calldata for its sharded data.
PDS however doesn’t implement any of the data sharding, PBS, or data availability sampling that’s a necessary part of danksharding. The state of affairs would essentially just be like being in an immediate post-Merge world, with a single proposer and 128-strong validation committee chosen randomly every 12-second slot, and with the committee being responsible for providing attestations. All full nodes would also therefore still need to download all of the data in the blocks, and as such, PDS is targeting block sizes of 1MB11 rather than the full 16MB projected via danksharding. (Current block sizes are around 85KB on average.)
Despite this relatively modest 1MB target, this still works out to about 2.5TB per year - a significant state growth rate. In order to limit this state growth, PDS is also proposing logic in the consensus layer to auto-delete blob data after 30 days. Whilst initially sounding like an alarming prospect, it’s worth noting two further points around this:
In the long run, adopting some sort of state history expiry mechanism is going to be essential. Danksharding would add about 40TB of historical blob data per year, so users could only realistically be expected to store a small portion of it for some time, hence it’s worth setting the expectations about this sooner rather than later.
The purpose of the Ethereum consensus layer is not to guarantee storage of all historical data forever, but rather to provide a highly secure real-time ‘bulletin board’, and leave room for other parties to do longer-term storage. It just needs to ensure data is available long enough for full nodes to query the data if necessary and for other interested parties (e.g. applications, block explorers, hobbyists, academics, indexing protocols, etc.) to have enough time to grab it for their needs. To complement this:
For these interested parties, purchasing hard drives to store an additional 2.5TB per year is unlikely to be prohibitively expensive.
Historical storage has a 1-of-N trust model: you only need one of the storers of the data to be honest. Hence, each piece of historical data only needs to be stored hundreds of times, and not the full set of many thousands of nodes that are doing real-time consensus verification.
This auto-deletion of blob data also ties quite nicely into the stated aims of the Purge development roadmap, which we’ll be discussing in a future post.
2.3.2 4844 and done?
The changes proposed by PDS are all forward compatible with danksharding. Moving to danksharding from a PDS world would then only require changes to the consensus layer, e.g. PBS, data availability sampling, etc.
But do we need to move to danksharding so quickly?
Assuming the minimum gas price is 7 wei, ala EIP-1559, EIP-4844 resets gas fees paid to Ethereum for one transaction to $0.0000000000003 (and that’s with ETH price at $3,000).
[…] With advanced data compression techniques being gradually implemented on rollups, we’d need to roughly 1,000x activity on rollups, or 500x activity on Ethereum mainnet, or 100x the entire blockchain industry today, to saturate protodanksharding. There’s tremendous room for growth without needing danksharding.
[…] Now, with such negligible fees, we could see a hundred rollups blossom, and eventually it’ll be saturated with tons of low value spammy transactions. But do we really need the high security of Ethereum for these?
I think it’s quite possible that protodanksharding/4844 provides enough bandwidth to secure all high-value transactions that really need full Ethereum security.
For the low-value transactions, we have new solutions blossoming with honest-minority security assumptions [such as] validiums […] with honest-minority [off-chain] DA layers.
Polynya goes onto to suggest that danksharding continue to be developed, simplified and battle-tested, with a gradual transition and later implementation date.
Having spent a reasonable amount of time getting my head around danksharding to write this post, and comparing it to the relative simplicity of PDS, polynya’s proposition is a compelling one. In the meantime, there is beginning to be a concertedeffort to get EIP-4844 developed in time for the Shanghai hard fork of Ethereum scheduled for later this year.
3 Next time on ‘After The Merge’
And that’s it! We got there in the end, and this is only discussing the Surge!
In the interests of my own sanity, I’ll stop there for now and save discussing the other post-Merge roadmaps for another time. Here’s a little taster though:
The Verge: Introduces Verkle trees, an upgrade to Merkle trees, which allows for builders to attach witnesses to their blocks, allowing validators to statelessly verify the blocks (i.e. not needing the state on hand to perform the validation role), leading to reduced node sizes and improved scalability. Users will be able to become network validators without having to store extensive amounts of data.
The Purge: Aims to prune historical data after a set period and eliminate technical debt, reducing network congestion and state bloat, and hence the hard drive space required by validators.
The Splurge: This captures the other developments that don’t quite fit into the other roadmaps (or didn’t at the time the roadmaps were initially created). PBS is one item which appears here but has been co-opted as a key element of danksharding. A notable item in the current Splurge roadmap is enshrined rollups, which eliminate governance and smart contract risk by allowing the deployment of entire rollups in-protocol, and would bring myriad benefits.
Thanks for reading himesh.eth! Subscribe for free to receive new posts and support my work.
Updated proto-danksharding design overview section to correct an earlier statement that calldata leads to state bloat, following a response from Dankrad Feist.
The terminology around nodes can get very confusing, with ‘full’ nodes used regularly in the literature to refer to either consensus (non-validation) nodes, validation nodes, or both. Based on the Ethereum documentation, I have taken full node as covering both consensus and validation nodes.
‘Other data’ consisting of erasure-coded extensions to the original data, KZG commitments, validity proofs, and the proposer’s signature, amongst other things. Erasure coding is explained later in the post; KZG commitments are mentioned below in footnote 4.
Signatures themselves, especially with large numbers of shards and validation committees, might also have added up to lots of GBs of data, exponentially increasing the size of Ethereum’s state. This would have been resolved with something called BLS signature aggregation: If Alice produced signature A, and Bob’s signature was B on the same data, then both Alice’s and Bob’s signatures could be stored and checked together by only storing C = A + B. By using signature aggregation, only 1 signature needed to be stored and checked for the entire committee. This would have reduced the storage requirements considerably.
Going further into the weeds, there is an additional question here which is: how can we be sure that the Layer 2 has performed the actual erasure coding correctly? They could have extended the block by 50% with essentially junk data, which would pass data availability sampling tests but prevent nodes from reconstructing the data. This has been solved by something called KZG commitments (alternatively called Kate (‘kah-tay’) commitments) which proves that all of the original and extended data lie on the same low-degree polynomial. This topic has been discussed at length in The Hitchhiker’s Guide to Ethereum, but won’t be discussed further here for the sake of brevity.
At the time of the Merge, an out-of-protocol version of PBS created by Flashbots called MEV-Boost will be available for validator nodes to use, which will allow them to outsource specialised block building if they wish.
Builders will be able to pass on block headers and bids to validator nodes (acting now only as proposers), much like PBS, except that these headers & bids will have to first run through ‘relays’, facilitating smooth commerce between the parties.
A relay will protect the builder from leaking any information about the block to the validators and ensure that even small validators can participate in the builder market. At the same time, the relay will protect the validator from receiving blocks that are invalid, overstate their bid to the validator, or are missing entirely. Relays will be able to connect to one or many builders; those connecting to many builders will be able see all the blocks submitted and associated bids, and will then only submit the highest valid bid to the validator to sign. Only after the validator then signs off on the block header will the body be revealed. MEV-Boost itself will effectively act as the relay aggregator, from which validators will choose which relays they wish to connect to. If MEV-Boost doesn’t pick up any relays, the validator node will naturally revert to local block building from the mempool.
MEV-Boost requires validators to trust the relays to not withhold blocks. To assess global relay performance and weed out bad actors, relay monitors are being designed.
This PBS implementation is rather unhelpfully known as ‘two-slot’ PBS, which can imply that a slot itself is being reduced to 8 seconds in length, and a block is only being finalised in every other slot (i.e. that an epoch of 32 slots will only have 16 blocks produced in it). Please note that this is not the case, and I have renamed these ‘slots’ as ‘stages’ in this post to provide this additional clarity.
The censoring builder could try to circumvent overbidding altogether by running their own validation nodes, but then they would have to wait for one of these nodes to be chosen as the proposer.
This refers to KZG commitments, previously discussed in footnote 4, although they would be used here for providing assurances around blobs rather than extended data.
Blobs are a fixed size (~125KB), and so to maintain a 1MB block size, 8 blobs per block is the target. The independent gas price for blobs is self-adjusting to ensure that in the long run the average number of blobs per block equals the target.